Overfitting
比如說,有以下圖片,圖片來源: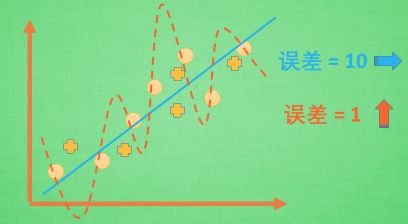
圓形代表訓練資料,十字形代表測試資料。
紅線能夠完美的表示所有訓練資料,誤差趨近於 0,
但是對於新的十字型資料就不那麼樂觀,誤差大幅飆升,
這種現象稱之為 Overfitting。
反之,藍線能夠同時表示圓形和十字型兩種資料,
並且誤差能維持在認可的基準下。
現實應用中,藍線才算是一個好的模型。
以機械學習的術語來說明,
訓練時很準確,測試時不準確,稱之為 Overfitting。
解決 Overfitting
增加數據量
隨著數據的增加,方程式為了適應更多的資料,
曲線會慢慢被拉直,變得沒那麼扭曲。
L1 L2 Regularization
透過 L1 L2 正規化,懲罰影響力過大的權重(W),
使得訓練過程不特別依賴某個權重(W),確保學習完的曲線不那麼扭曲。
Dropout Regularization
在訓練的時候,Dropout 正規化會隨機忽略掉一些神經元和神經連結,
使得神經網絡變得不完整,緊接著用這個不完整的神經網路訓練一次;
第二次訓練再隨機忽略掉另一部分神經元和神經連結。
同 L1 L2 正規化,Dropout 正規化使得訓練過程不會過度依賴某個權重(W)。